
Overview
High Performance Computing (HPC) has recently been commoditized with the advent of commodity server hardware (x86 server), virtualization technology and cloud delivery model. It is common in specialized industries where intensive computing tasks are required, for example:
- HCL (healthcare and life science): drug discovery, computer aided diagnosis (CAD), genome engineering;
- CAD, CAE, CAM (computer aided design, engineering, and manufacturing): 3D modeling, computational fluid dynamics (CFD), finite element analysis (FEA), structural mechanical design, etc
- Finance: portfolio management, automated trading, risk analysis
- Geoscience and geo-engineering: oil and gas exploration, geographic data, weather forecasting;
- Scientific computation
Computing performance is measured in FLOPS (floating point operations per second) and is usually delivered in a cluster to aggregate the computing power from a number of networked nodes. This is referred to as an HPC cluster.
Hardware stack
An HPC cluster features the following components:
- Head node (aka master node or login node): a gateway and coordinator; head node may be broken into several nodes
- Compute node (worker node): the executor of jobs; the compute node can either be homogenous or heterogeneous, for different purposes. the number of compute nodes can be quite large
There are four common form factors for server: tower, rack-mount, blade, mainframe. Traditionally, the nodes are rack-mount 1U “pizza box” servers. Bladed systems started to replace due to the increased node density, thanks to the shared/redundant power and cooling management. In the past, the HPC cluster is operated in data centres, which is an expensive operation item. In the last decades, many organizations extends their compute workload to the cloud, forming a hybrid model.
HPC typically has specialized storage system because HPC applications notoriously create large amounts of data. NFS traditionally does not scale well as number of node increases. Some proprietary storage system such as Isilon provides good performance via NFS protocol. There are also open-source parallel file system such as Lustre and HDFS.
HPC networking handles three types of traffic:
- computation traffic between compute nodes (if the compute nodes interact with each other)
- file system traffic: for compute nodes to read and write on file system (e.g. NFS)
- administrative traffic: fairly light compared to the two above
For that, many HPC runs two networks, a private (backend) network and a public (frontend) network. Backend network must be high speed and low latency, typically in the form of 10Gig Ethernet, or InfiniBand.
Software stack
On the software layer, the core functionality is Message Passing Interface (MPI), a specification for the developers and users of message passing libraries. MPI constitutes a standardized and portable message-passing system which consists of a library and a protocol to support parallel computing. MPI enables passing information between various nodes of a HPC cluster or between particular clusters, and has different implementations that provide the libraries to run HPC applications in a distributed manner across different physical nodes.
In the operation, user submits a job through head node in order to request the resource. User needs to specify the resources for the job (e.g. how many CPU cores, how much memory, etc). The head node runs a scheduler to allocate computing resource based on pre-defined policies, based on priority of jobs, availability of resources, distribution of load, etc. Depending on the nature of the computing jobs, the nodes participating in the task may or may not communicate with one another. If they do need to talk to each other, the program must support it. Such program can be called a cluster program, and the MPI (message passing interface) library greatly facilitates the development of such program. The sub-jobs communicating with each other also creates a considerable amount of network traffic within the cluster.
Cluster software ties all nodes in the cluster together. It turns raw hardware into a functioning cluster by provisioning (installing and configuring) the head nodes. Compute nodes can usually be added or removed dynamically therefore the head nodes should be able to provision compute nodes, and administer cluster, leaving the programming as the job for the user to complete. As mentioned, in parallel programming, the most important HPC tool is MPI (Message Passing Interface), which allows programs to talk to one another over cluster networks. There are both open (e.g. Open MPI) and commercial MPI (e.g. Microsoft MPI) versions. Cluster software should also provide compilers, debuggers, and profilers in addition to MPI.
There are cluster software in both Linux and Windows operating systems: Rocks Clusters, Oscar (Open Source Clusters Application Resources), Red Hat HPC solution, Microsoft HPC pack and AWS Parallel Cluster.
Implementation
Here is an example of setting up HPC cluster with CentOS. Despite of the well documented steps, note that the author of the document refers to HPC cluster simply as cluster, which is ambiguous. There are three basic motivators for creating a cluster: high performance computing (HPC), network traffic load balancing, and service resilience in the form of high availability (HA). The author should be specific in the document about the HPC cluster. If RDMA (Infiniband) network is involved, a configuration guide is provided in RedHat literature.
Here is an example of deploying HPC cluster in AWS. Here is the guide to deploy HPC pack in Microsoft technologies.
HPC and Big Data
HPC and Big Data are two distinctive computing paradigmes. Although there is some signs of convergence and blurred boundaries, it is still a long way before one can treat HPC and Big Data interchangeably. This paper does a phenomenal job in comparing the two paradigms.
The fundamental difference lies in the respective problems they intend to address. HPC focuses on the large computational loads, whereas Big Data targets applications that need to handle very large and complex data sets (usually in the order of multi-terabytes or exabytes). Many scientific data analytics applications are becoming I/O bound in modern systems, such as seismic algorithms, Big Data applications are thus very demanding in terms of storage, to accommodate such a masive amount of data, while HPC is usualy thought more in inters of sheer computational needs. The open-source projects in Big Data also aims to run on conventional hardware to make it easier and less expensive to scale. This is not the main focus of HPC.
So, you can run Big Data (e.g. Hadoop) analytics jobs on HPC gear. On the other hand, you can’t run HPC jobs on commodity hardware as commonly seen in the Big Data stack. Both HPC and Hadoop analytics use parallel processing of data. In a Hadoop/analytics environment, data is stored on commodity hardware and distributed across multiple nodes of hardware. In HPC, where the size of data file is much greater, data storage in centralized. Also, because of the sheer volume of its files, HPC also requires more expensive networking communications such as Infiniband, because the size of the file it processes require high throughput and low latency.
In BigData job, each query in Hadoop reads data from disk and runs as a separate MapReduce job. Spark enables in-memory iterative processing (through the RDD abstraction), allowing the user to query repeatedly on a dataset without having to perform intermediate disk operations. RDD are exposed in the Spark API where each dataset is represented as a read-only object, and transformations are invoked using methods on these objects. For an example project, check out this post.
The underlying software stacks for HPC and Big Data are fundamentally different, mainly due to the differences represent in their target class of applications, as outlined in the diagram below:
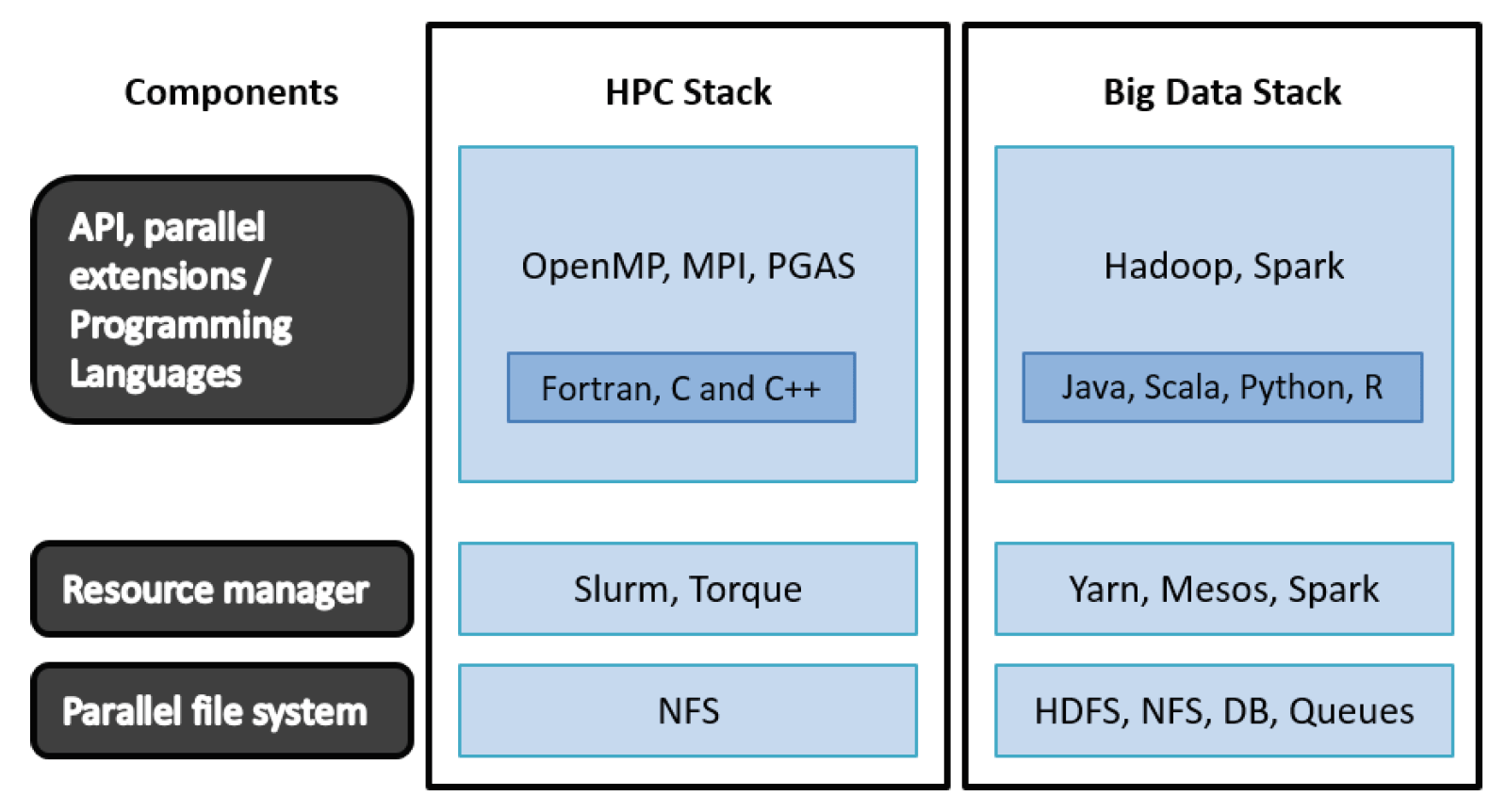
As to which one is for me, the over-simplified advice is: if you can avoid HPC and just use Hadoop for your analytics, do it. It is cheaper, easier, and more cloud friendly. However, bear in mind that an all-Hadoop shop is not possible for many industries such as life sciences, weather, pharmaceutical, and academic applications.