

Machine learning workflows are highly experimental. To smooth out the processes, Amazon SageMaker AI packages many features as managed services. As an infrastructure specialist, I want to remain compliant. At a basic level, compliant architecture means multi-account structure and hub-and-spoke VPC topology in a landing zone. While the multi-account operating model for SageMaker is well documented, these ML managed services obscure the network configuration. I’m always looking for low-level insights on where the computing activity is happening and how the application traffic flows in and out of our VPCs. I don’t always get straight answers and I often have to experiment them out. This post is a review of the networking aspects of SageMaker AI I recently learned.
Naming Shenanigans
Unfortunately, I have to start with how AWS has renamed these services, so the terms remain clear throughout the post.
In Dec 2024, AWS renamed SageMaker to SageMaker AI. The name of SageMaker going forward represents the overarching AWS service for machine learning, data, analytics and generative AI. Here is a video for clarification. I’m not a fan of how they repurpose the names. As of date there are still a lot of content referencing SageMaker AI as SageMaker, whose meaning has changed.
If that’s not enough, here’s another one. The SageMaker Studio launched originally in 2019 for model development. In 2023 that became SageMaker Studio classic, in favour of the newly launched studio, taking the name of SageMaker studio. In Feb 2025, AWS deprecated SageMaker Studio classic. You can only create SageMaker Studio in SageMaker AI.
At the SageMaker level, AWS launched SageMaker Unified Studio, the all-encompassing development environment for data analytics, generative AI, and so on. In this post though, we talk about many features under SageMaker AI and SageMaker Studio. While the service UIs are picturesque, we remain focused on two questions: how these services interact with resources on our VPCs, and how they connect to the Internet.
Workload Categories
We divide machine learning workload into three categories, based on network connectivity pattern: notebooks, model hosting, and pipeline jobs.
Notebooks are where data scientists carry out experiments by running experimental scripts on performing hardwares (depending on the tasks), usually within IDE application as Jupyter Labs, Code Editors. Data scientist users may perform any machine learning related activities such as model evaluation, etc. It is possible that one part of a notebook only requires consumer grade CPU and another part of the notebook program requires a performant GPU. It all depends on the nature of the program code.
Model is the key artifact in Machine Learning workflows. Models themselves are files stored in S3 buckets. The machine learning engineers performs two most common activities. They train the model, and feed the model with unseen data for new output (inference). In simple workflows, data scientists may build, train a model and run inference all from within the same notebook. As the experiment concludes and the team wants to operationalize the inference, it makes senses the run inference in a client-server architecture. This calls for a inference endpoint acting as the server, backed by the trained model, operating on a single or an autoscaling group of instances. The client application feeds the endpoint with unseen data, often using REST API calls, and expects inference results.
Pipeline steps like training do not operate on a server. They are similar to Notebook workloads. The difference is that pipeline steps are headless executions. The steps are non-interactive without engaging the Studio GUI. Many other types of activities in machine learning are in similar pattern, such as model evaluation, model optimization or any general processing such as a Python script. I consider them similar to training activities. Since we orchestrate these headless activities with pipelines (e.g. SageMaker pipeline), and each step may execute on some specialized instance depending on the computing requirements. Collectively, I call these activities the pipeline jobs.
Let’s look at these workloads through the networking lens.
Studio Notebooks
The most common Studio app is some kind of notebooks, such as Jupyper Lab. However, this category can generally include all kinds of SageMaker Studio apps, e.g. Canvas, Code Editor. I use the term Studio app and Studio notebook interchangeably but the APIs mostly refer to these as apps, such as AppNetworkAccessType.
In the app, a user may create one or more spaces each specifying the backing instance type. The configuration that influences the instances’ networking setup is in SageMaker AI domain’s Network Setting. There are two parts of this AppNetworkAccessType setting:
- Network Mode (also called AppNetworkAccessType in AWS SDK):
- PublicInternetOnly (default): only EFS traffic goes through the specified VPC and subnets. Other studio traffic (e.g. API calls) goes through the Internet Gateway of the VPC that the studio manages internally
- VpcOnly: all studio traffic goes through the specified VPC and subnets. This delegates the responsibility of connectivity to endpoints to the VPC’s owner.
- VPC and Subnet: to place EFS mount points on. Also route other studio traffic in VpcOnly mode.
There are one diagrams on the documentation for each network mode (PublicInternetOnly on the left; VPCOnly on the right):
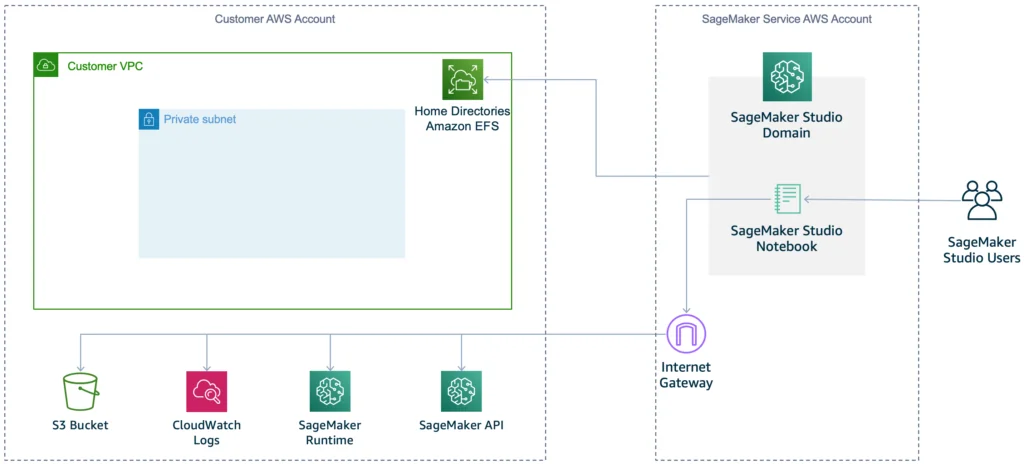
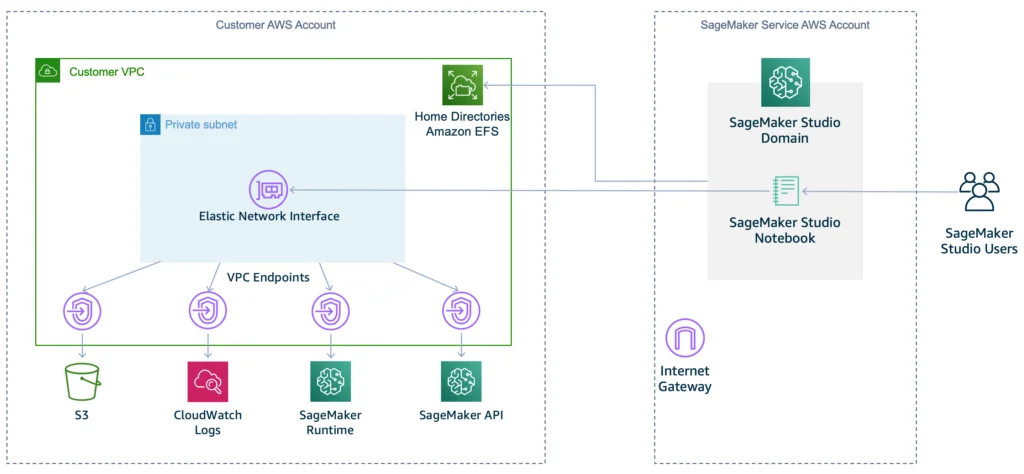
The diagrams (as of March 2025) are not accurate because the PublicInternetOnly mode also has a domain managed ENI per app space. The VpcOnly mode is when the ML do not like the idea that a Notebook instance can bypass centrally managed Internet path. The team must ensure the endpoints are reachable, either via Internet, or via routable VPC endpoint (e.g. Gateway Endpoint for S3 and Interface endpoint for the rest). In a hub-and-spoke setup it might be another dedicated VPC that provides the interface endpoints centrally.
The domain settings include a few configurations on the underlying instance. For example, SecurityGroupIds specifies the security groups associated with the ENIs. DockerSettings enables Docker daemon on the instance, allowing users to test container workload in local mode. Note that in the more constraint VPC-only mode, Docker pull and push operations outside of Amazon Elastic Container Registry aren’t supported. To pull or push from ECRs users also need to white-list account IDs of the private ECRs in the VpcOnlyTrustedAccounts setting.
In comparison with the other two types of workload, the network traffic for studio notebooks are the easiest to control because they are all configured at the SageMaker AI domain level. Once users with user profiles under a domain creates a notebook, the domain or user profile determines the network mode, and subnet values and security groups. Users themselves cannot change these settings.
Inference Endpoint
The machine learning realm has a few established programming frameworks to host a model file behind an inference endpoint. For example, TensorFlow, PyTorch, Scikit-learn, and even Fast API. Amazon SageMaker AI supports many such frameworks and makes it straightforward. Managing the frameworks requires complex dependency management, a typical use case of containers. Apart from choosing a proper container image, user also selects instance types. These machine learning special purpose instances are pricier than their commodity counterpart. In low-traffic workflows, users may provision inference endpoint on-demand and use it in a controlled time-window, or just use serverless inference endpoint if the model supports it.
When creating inference endpoint, the CreateModel API is used. Under the VpcConfig attribute, two parameters are at play: Network Isolation and VPC-Subnet configuration. I summarize them as below based on the documentation:
| Network Isolation | VPC-Subnet Configuration | Description |
|---|---|---|
| Disabled | Not specified | SageMaker AI containers are able to access external service and resources on the public Internet; but not able to access resources inside your VPC |
| Specified | SageMaker AI containers communicate with resources inside your VPC through an ENI (Elastic Network Interface). Users are responsible for managing network access to your VPC and Internet. | |
| Enabled | Not specified | SageMaker AI container cannot communicate with resources inside your VPC or on the public Internet |
| Specified | The download and upload operations are routed through your VPC, but the inference (and training) containers themselves continue to be isolated from the network, and do not have access to any resource within your VPC or on the internet. |
The Network Isolation option governs the container connectivity option. If we do not expect the inference activity to make outgoing network calls (except for downloading artifact and packages), then we should enable network isolation. On the other hand, if the inference container needs resources on VPC or on the Internet, disable network isolation. Either way, we specify the VPC so that we manage the routing through VPC.
In a compliant networking setup where Internet access must be centralized, the VPC-Subnet configuration must always be configured. The network isolation value depends on the nature of inference workload. However, what seems to be missing in the Studio UI is the activity to enforce that VPC-Subnet configuration is always specified.
As a workaround, we can use the SageMaker Domain’s IAM role to contain such attempt at API level. Below is an example of deny policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"sagemaker:CreateModel"
],
"Condition": {
"BoolIfExists": {
"sagemaker:VpcSubnets": "false"
}
},
"Effect": "Deny",
"Resource": "*",
"Sid": "DenyModelcreationIfNotOnVPC"
},
{
"Action": [
"sagemaker:CreateModel"
],
"Condition": {
"ForAnyValue:StringNotEquals": {
"sagemaker:VpcSubnets": [
"subnet-999999999999999",
"subnet-111111111111111"
]
}
},
"Effect": "Deny",
"Resource": "*",
"Sid": "DenyModelcreationIfAnySpecifiedSubnetIsNotIntended"
}
]
}
We can use this policy in conjunction with the AmazonSageMakerFullAccess managed policy. The request to create a mode gets denied, either if VpcSubnets are not specified, or they are but not from the preset list of subnet IDs. Once the user selects subnets, corresponding ENIs will get created in the subnets too and user needs to specify security groups for the ENIs.
Enforcing in IAM policy requires that the user who creates endpoint either on SageMaker Studio UI or SageMaker SDK must know the exact subnet IDs as well as appropriate security groups. This requires access to the VPC and can turn into an operation pain point if the users are not well versed with networking. Ideally subnet configuration should also be enforceable at the domain level.
Pipeline Jobs
Most machine learning jobs do not need to function behind an endpoint (i.e. server-side), for example, training, labeling job, model optimization, hyper parameter tuning, etc. In operation, we often use a pipeline to orchestrate these short-lived, non-interactive, headless jobs. Therefore, I simply refer to them as pipeline jobs. They sometimes rely on special purpose instance types. In most cases, they need access to either the Internet or other resources available via customer VPC, a connectivity pattern similar to that of interface endpoints.
To create such resources, SageMaker AI domain user either operate on SageMaker Studio, or program with SageMaker SDK. To make it easy to specify network isolation and subnet configurations, the SDK even has a class for NetworkConfig that can pass to many types of processors (steps).
from sagemaker.network import NetworkConfig
security_group_ids = ['sg-#']
subnets = ['subnet-#']
enable_network_isolation = True
network_config = NetworkConfig(
security_group_ids=security_group_ids,
subnets=subnets,
enable_network_isolation=enable_network_isolation
)
script_processor = ScriptProcessor(
image_uri='my-script-processor-image',
command=['python3', 'script.py'],
instance_type='ml.m5.large',
role=role,
network_config=network_config
)
The network_config parameter exists as an argument in the creation method of many other resources via SDK. However, the SageMaker UI domain does not have a mechanism to enforce it one way or another. Leaving this option open to users is not what every organization wants either. We could exercise control as much as we can with condition keys such as sagemaker:VpcSubnets in the deny policy for SageMaker IAM role as the example above shows. The Service Authorization Reference document lists out in which SageMaker SDK calls the sagemaker:VpcSubnets condition key (or equivalent) exists. A proactive IAM policy to safeguard all the applicable SDK calls would be helpful as a workaround to the missing enforceability at domain level for SageMaker AI.
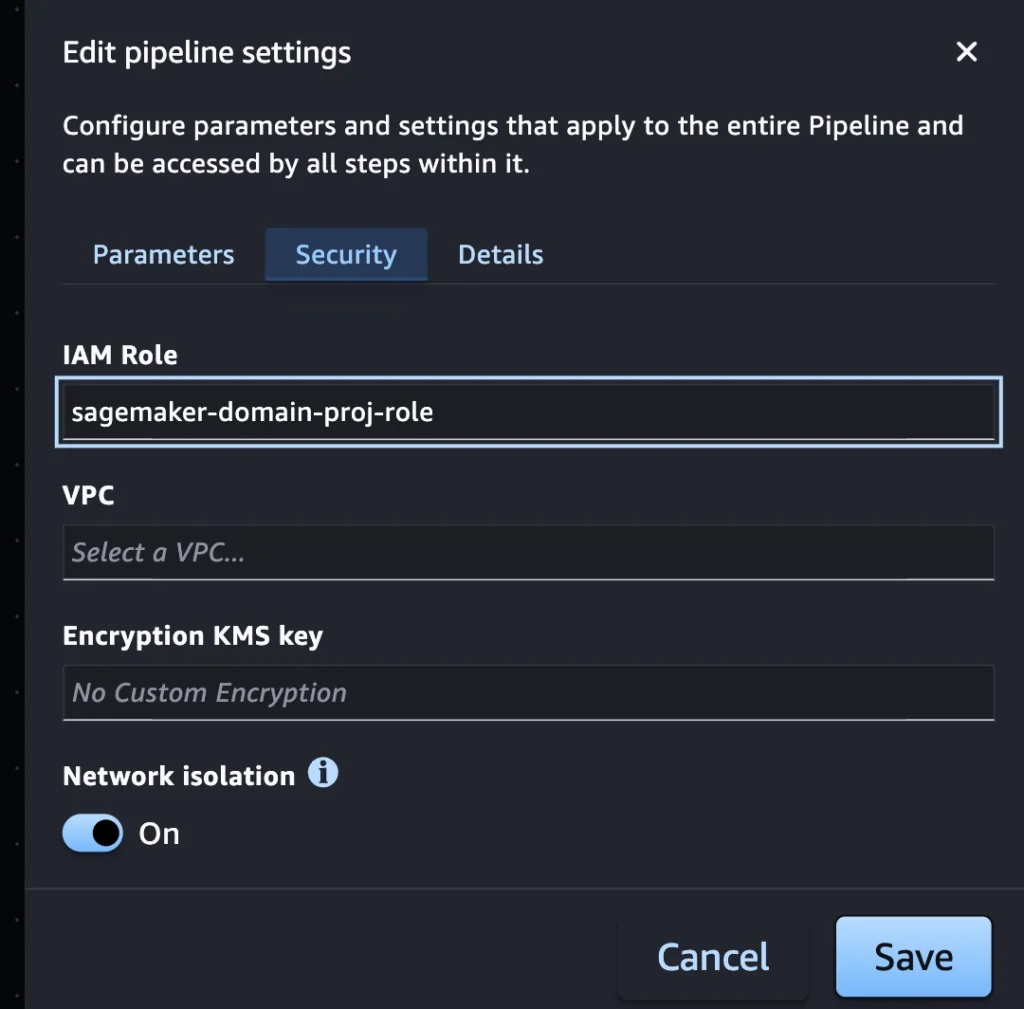
Note that on the SageMaker Studio’s Pipeline tool there is a Network configuration seemingly for the pipeline. However, the CreatePipeline SDK call does not have an argument about network configuration. The PipelineDefinition argument requires a JSON format input to define the pipeline configuration and the network configuration is defined per step in the definition.
Another perspective to look at this issue is how we can give a pipeline step (or in general any job runtime) the flexibility to connect to Internet, and in the mean time remain in control of its network connectivity. It depends on the intended security posture but we mainly look at these two questions on the requirement:
- can the job runtime access the VPC?
- can the job runtime access the Internet on its own path?
Depending on the answer, we can configure a Job in three ways:
| Configuration | Description | |
|---|---|---|
| a | Neither #1 or #2 are allowed | Most secure but might be overly restrictive because the job runtime may need to download artifacts. This requires enabling Network Isolation and specify VPC-Subnet configuration. |
| b | Either #1 or #2 is allowed, but not both at the same time. | Exclusively allowing #1 is more secure because the VPC can manage access to Internet for the job runtime. Exclusively allowing #2 breaks the central Internet access pattern and should not be allowed if central Internet access is a compliance requirement. |
| c | Both #1 and #2 are allowed at the same time | This configuration should not be made possible due to exfiltration risk. |
This classification of network configuration for ML pipeline job, is quite similar to DevOps pipeline job agent (think of Azure DevOps agent or Terraform agents). The user may use service provider’s agent which come with its own Internet access, or choose to self-host the agent to allow access to VPC but the VPC’s owner is then responsible for managing Internet routing through the custom VPC.
SageMaker AI makes c impossible, which is good. SageMaker administrator needs to evaluate the requirement between a and b and determine how to enforce it with IAM policy.
Summary
As an infrastructure security specialist, I investigated networking options in SageMaker AI. When any user is performing any task in SageMaker AI, I am concerned with two questions:
- How does the instance behind the endpoint connects to the internet and to our VPCs;
- How do we enforce the connectivity pattern (enforceability);
For the studio notebooks workload, the control is through SageMaker domain. For Inference endpoint and pipeline jobs, the control is reactive. We use IAM policies and role to deny attempts to create resources with bad network configuration. The limitation is that the SageMaker users have to know what network configuration options are available.
As a result, the infrastructure security specialist must clearly define the required network configuration, and communicate it out to SageMaker AI users.