
For someone from a system administration background, it would be amazing to discover that Kubernetes provides a solution to every pain point in the traditional software deployment landscape. On the contrary, it also brings about a lot of complexity due to the types of resource objects introduced.
A Pod is a shared execution environment for one or more containers. The containers running in a Pod share resources such as memory, volumes, network namespace (e.g. IP address, port range, hostname, routing table), UTS namespace (e.g. hostname) and IPC namespace (Unix domain sockets). Every Pod has its own IP address that is routable on the Pod network. All Pods connect to the same flat network called the Pod network.
A pod most commonly only contains a single container, which is considered a good practice, unless there is good reasons to put two containers in a single pod (sharing resource). One such good reason is to co-schedule tightly-coupled workloads (such as logging, sharing volume, etc). Within the Pod, the containers communicate with each other via localhost interface of the Pod. In service mesh model, there is also a proxy container in each application Pod. The proxy container handles all network traffic entering and leaving the Pod. Also, within the Pod, to avoid competing for resources, individual containers can have their own cgroup limits, which actively police resource usage.
Pods are mortal (composable). They come and go (with dynamic IPs), so application should not store state in Pods. Deploying a Pod is an atomic (all or nothing) operation. When a Pod is scheduled to a node, it enters the pending state while the container runtime on the node downloads images and starts any containers. Once’s everything is ready, the Pod enters the running state.
We typically deploy Pods via higher-level controllers such as Deployments (to offer scalability and rolling updates), DaemonSets (to run one instance of a service on every node in the cluster), StatefulSets (for stateful application components), and CronJobs (for short-lived tasks that need to run at set times just like a Linux cronjob).
Deployment manages multiple replicas of the same Pod (via ReplicaSets). To follow best practice, you interact with Deployments instead of ReplicaSets, and use YAML file (declarative model). You can perform rolling update or rollback.
ReplicaSets provide self-healing and scaling capabilities to Pods. If a Pod fails, it will be replaced. If load increases, then the ReplicaSets creates new Pod. This is all implemented with a background reconciliation loop that is constantly checking whether the right number of Pod replicas are present on the cluster. If not, Kubernetes declares a red-alert condition, orders the control plan to bring up more replicas. The best practice however, is that you should not manage ReplicaSets directly. Instead, you should perform all actions against the Deployment object and leave the Deployment to manage ReplicaSets.
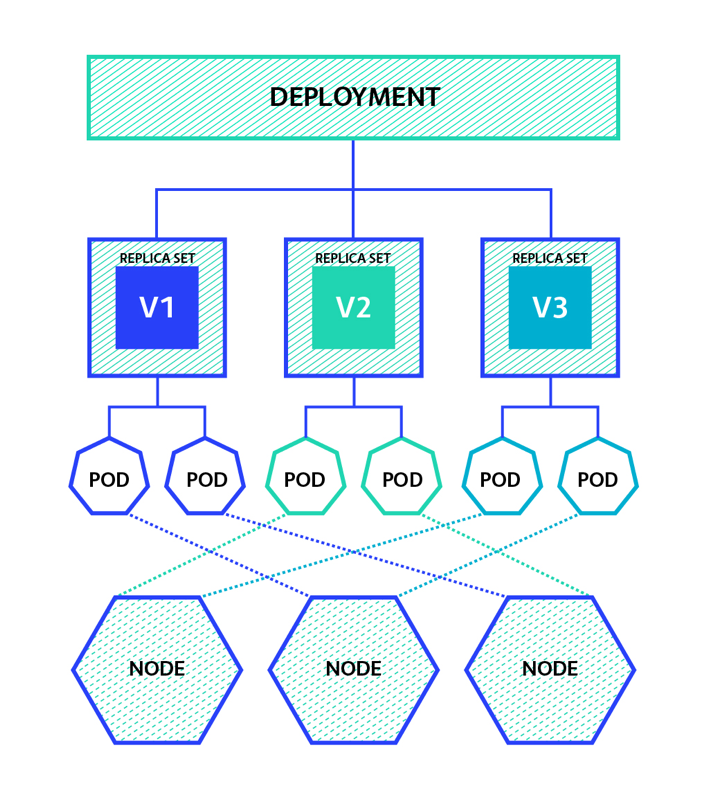
Pods themselves are mortal (IP churn) so it’s a bad idea to talk directly to individual Pods. Service object provides stable and reliable networking for a set of dynamic Pods. Service gets its own stable IP address, stable port and stable DNS name. It can also load-balance request across the Pods.
Services are loosely coupled with Pods via labels and label selectors. You specify label selector for Service and labels on Pods when creating them. All the labels in label selector are used to select target Pods. Service acts as front-end, consisting of stable IP, DNS name and port, with Pods acting as backend, consisting of constantly changing Pods. Labels are simple yet extremely powerful. During blue-green update, you may use version label as a technique to control what backend pool is used behind Service object. For example, start with version=1, deploy version 2, remove version from label selector, and eventually add version=2 back to label selector, before phasing out the old Deployment.
Services learn Pod status via Endpoint object, more details to follow.
There are several types of Service, the default being ClusterIP. A ClusterIP Service has a stable IP address and port that is only accessible from inside the cluster. The ClusterIP gets registered against the name of the Service on the cluster’s internal DNS service (implemented via coreDNS with Control plane Pods). This means that the ClusterIP only works within the cluster, not outside. The other type of Service is called a NodePort, which is built on top of ClusterIP, but also enables access from outside of the cluster. The Service object has a reliable NodePort mapped to every node in the cluster. The NodePort value is the same on every cluster. Traffic from outside of the cluster can hit any node in the cluster on the NodePort and get through the the Pods.
Other types of Services include LoadBalancer and ExternalName. LoadBalancer Services integrate with load-balancers from cloud provider. They build on top of NodePort Services and allow clients on the internet to reach your Pods via the load balancer of cloud vendor. ExternalName Services route traffic to systems outside of your K8s cluster.
For service discovery within the cluster, Kubelet program every container with the knowledge of the internal DNS (/etc/resolv.conf). The internal DNS service watches constantly the API server for new Services and automatically register them in the DNS. The other means of service discovery is through environment variables. However, in this method the Pods have no way of learning about new Services added to the cluster after the Pod itself is created.
Endpoints object is a dynamic list of all the healthy Pods on the cluster that match the Service’s label selector. Each Service gets its own Endpoints objects for an up-to-date list of matching Pods. Kubernetes is constantly evaluating the Service’s label selector against the currently list of healthy Pods on the cluster. Any new Pods that match the selector get added to the Endpoints object, and any Pods that disappear get removed.
When sending traffic to Pods, via a Service, an application will query the cluster’s internal DNS for the IP address of a Service, then sends the traffic to this stable IP address. Service then forwards it on to a Pod. Kubernetes-native application however, has the ability to query the Endpoints API directly, bypassing the DNS lookup and use of the Service’s IP.
It requires a thorough understanding of Services, Endpoints and the service discovery mechanism to perform effective troubleshooting in Kubernetes.
The aforementioned internal DNS service (we usually call it the “cluster DNS”) is implemented in the kube-system Namespace as a set of Pods managed by a Deployment called coredns. These Pods are fronted by a Service called kube-dns. The cluster DNS is constantly looking for new Services and automatically register their details (metadata.name). We might need to check the logs for each of the coredns Pods during troubleshooting.
The kubelet process on every node is watching the API Server for new Endpoints objects, when it sees them, it creates local networking rules that redirect ClusterIP traffic to Pod IPs, using IPVS technology on Linux to manage these rules.
A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
Some typical uses of a DaemonSet are: cluster storage daemon on every node, logs collection daemon on every node, a node monitoring daemon on every node.
The Horizontal Pod Autoscaler automatically scales the number of Pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization (or, with custom metrics support, on some other application-provided metrics). Note that Horizontal Pod Autoscaling does not apply to objects that can’t be scaled, for example, DaemonSets.
The Horizontal Pod Autoscaler is implemented as a Kubernetes API resource and a controller. The resource determines the behaviour of the controller. The controller periodically adjusts the number of replicas in a replication controller or deployment to match the observed average CPU utilization to the target specified by user.
There are more details about HPA here and here.
StatefulSets are designed for stateful application, which creates and saves valuable data. The three properties that form the state of a Pod are:
- Pod names (<StatefulSetName>-<Integer>)
- DNS hostnames
- volume bindings
They are sometimes referred to as the Pods sticky ID. StatefulSets ensures that these are all predictable and persistent. For example, failed Pods managed by a StatefulSet will be replaced by new Pods with the exact same Pod name, the exact same DNS hostname, and the exact same volumes, even if the replacement Pod is started on a different cluster Node.
Note that StatefulSets create one Pod at a time, and always wait for previous Pods to be running and ready before creating the next. Scaling operations are also governed by the same ordered startup rules. This is different from Deployments that use a ReplicaSet controller to start all Pods at the same time, causing potential race conditions. The way StatefulSet controllers do their own self-healing and scaling is architecturally different to Deployments which use a separate ReplicaSet controller for these operations. The reason it is a game changer to know the order in which Pods will be scaled down, as well as that Pods will not be terminated in parallel, is because clustered apps that store data are usually at high risk of losing data if multiple replicas go down at the same time.
Deleting a StatefulSet does not terminate Pods in order. So you may want to scale a StatefulSet to 0 replicas before deleting it. You might also set 10 seconds grace period before terminating to allow applications a chance to flush local buffers and safely commit any writes still in flight.
In Kubernetes, Volumes are decoupled from Pods via PersistentVolumes and PersistentVolumeClaims. So volumes have separate lifecycles to Pods and can survive Pod failures and termination operations. When a StatefulSet Pod is created, any volumes it needs are created at the same time and named in a way to connect them to the right Pod. Any time a StatefulSet Pod fails or is terminated, the associated volumes are unaffected. This allows replacement Pods to attach to the same storage as the Pods they’re replacing, even if the replacement Pod is scheduled to a different cluster Node. Similarly, if a StatefulSet Pod is detected as part of a scale-down operation, subsequent scale-up operations will attach new Pods to the existing volumes that match their names.
Since each StatefulSet Pod needs its own unique storage, hence its own PVC, this can be done by volumeClaimTemplate, which dynamically creates a PVC each time a new Pod replica is dynamically created. This eliminates the hassle to have to pre-create a unique PVC for every potential StatefulSet Pod.
Namespaces allows you to partition resource objects. For example, you may create a Namespace called prod and dev. Object names must be unique within Namespaces but not across Namespaces.