
A BitBucket repo has a hard limit of 2GB in size, and soft limit of 1GB. This is not expandable as per Bitbucket and contributors will start receiving warnings once soft limit is reached. We can tell the usage of a repo from the landing page of the repo in BitBucket.

Git is a distributed version control system for source code management, which implies the followings:
- It is intended for source code, or configuration code; but not for storing build artifacts, or installers;
- Git remembers every single commit, including the ones associated with large files;
- Even a contributor deletes a large file (“git rm filename”) after commit, the large file is only removed from the HEAD. The historical commit still stores the file. After all, the whole point of version control is to survive crazy deletion.
- distributed means that those large files will be pulled down to contributors laptop (waste everybody’s space although up to 2G:);
With all these implications, shrinking the size of a repo isn’t as straightforward as just removing large files from current commit. We’d have to rewrite the commit history. Here are the steps we should take once repo size grows over the soft limit.
Clean up remote orphaned branches
Removing these branches (remotes/origin/branchname) per se does not free up space. It simplifies the branch structure, leaving /remote/origin/HEAD the only branch left to cleanse for the rest of the steps.
# git push origin --delete branchname
Remove useless files in current commit (HEAD)
In this step we remove useless files in current commit. Again we should not expect much space freed because all file committed previously, even deleted, are still stored. They are just now showing up in the working directory. For this step, we can create a separate local dir on Mac:
mkdir -p /Users/digihunch/repo-cleanup
cd /Users/digihunch/repo-cleanup
Now within the new directory, we create a bare repo and then the full repo:
git clone --mirror https://[email protected]/digihunch/source.git
git clone https://[email protected]/digihunch/source.git
Then we dive into the full repo and identify the large files:
find . -type f -size +1000k -exec ls -lh {} \; |awk '{print $9":" $5}'
We can run “git rm ” against the files identified as too large or deletable. Then commit and push to remote repo. This removes large files from current commit.
Remove large file and the relevant commits in the history
As previously mentioned, we have to re-write the history so history forget about the large files. After this step, the historical commits that large files are associated with will all be deleted. Compare the two charts below to understand what the effect is:
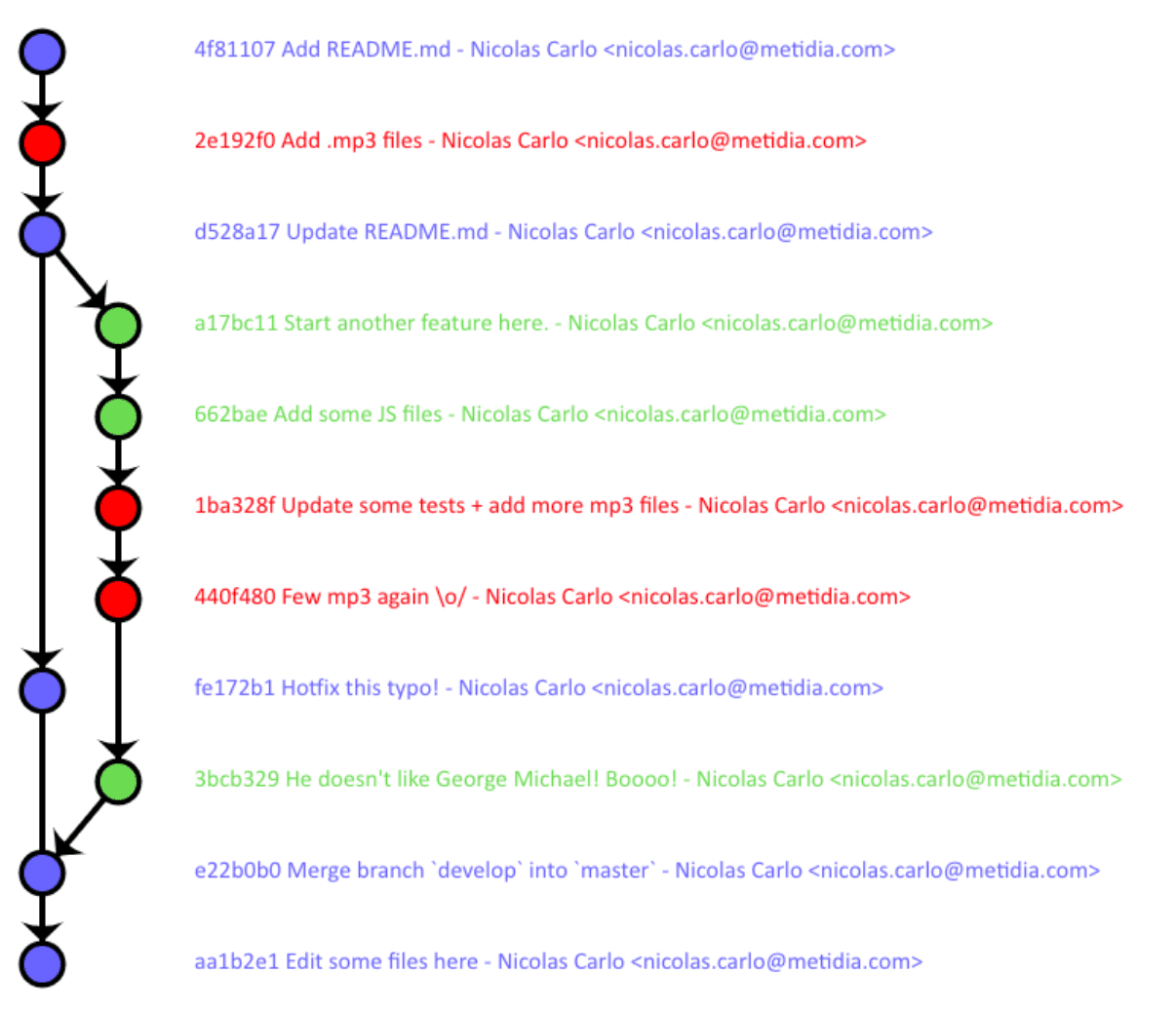

We can use the bare repo created in the last step, with “git filter-branch” tool to cleanse the branch tree. Some advocate as a faster third party tool BFG Repo-Cleaner as a faster, third-party alternative but I usually lean towards native tool. This article explains the command switches.
git filter-branch -f --tree-filter "rm -rf \large_file.zip" --prune-empty -- --all
After this steps the repo should be cleansed. According to this guide from BitBucket, we still need to contact their support to run a garbage collection for us in order to see the size change. It even takes time for the size to be reflected after garbage collection. This reference also does great job explaining what we need to do.
Other contributors re-sync history
It is important to understand that the step above modifies history. Although the commit hash did not change, they are assigned with different commit-ids and you can tell from the commit history where it displays former commit id.
This activity only affects remote repository. Each contributor’s local repository still stores the old commits and should be sync’ed with the remote origin by deleting the entire repo and run “git clone” again. Although not welcomed by every individual contributors, but it is a necessary evil and better approached with explicit instruction.
Because this activity takes higher risks, changes each commit, involves vendor support and requires activities by each contributor, the support team should focus on preventing this from happening instead of fixing it.
Configure pre-commit hook as a preventive measure
As we have more Ansible tasks related, working directory becomes complicated and sometimes contributors accidentally committed large unwanted files (and pushed into the remote repo). Down the road, the best practice is to prevent contributors from committing junks.
The best spot to detect this should be a pre-receive hook on the server side, which is only available with self-hosted Bitbucket Server. Unfortunately, this is not a viable option for Bitbucket cloud. Our best bet is client-side pre-commit hook, in which a script performs size check when contributors run “git commit”. The purpose is to fail the commit if total file size is over the limit (20M), and the hook itself should be version controlled as well. Compared to (server side) pre-receive hook, the drawback of (client side) pre-commit hook is it requires initial client configuration. The upside is it captures large files before commit.
This hook can be a shell script as simple as this:
commitsizelimit=20
stagedfilelist=$(git diff --name-only --cached)
stagedfilecnt=`echo "$stagedfilelist"| sed '/^\s*$/d' |wc -l`
if [[ $stagedfilecnt -gt 0 ]]; then
totalcommitsize=$(du -cm $stagedfilelist | tail -1 | cut -f 1)
# Redirect output to stderr.
exec 1>&2
if [[ $totalcommitsize > $commitsizelimit ]]; then
echo "Warning: Total size of all files in staging area is "$totalcommitsize"MB, exceeding the limit of "$commitsizelimit"MB."
echo " To list files by size, run 'du -ch \$(git diff --name-only --cached)'"
echo " To drop large ones from staging area with 'git rm -f filename'"
echo " To bypass this limit, use 'git commit --no-verify'"
exit 1
fi
fi
In the repo we will have a .githook directory to store hooks (e.g. ~/source/.githooks/pre-commit) and point to the hooks directory using the following command:
git config core.hooksPath .githooks