

Silicon Valley startups in mid-2000s likely do not run their own IT operations (i.e. renting their own data centre spaces, purchasing their own rack-mounted servers). Since the launch of EC2, AWS has been renting extra computing capacity to those startups, in the IaaS model. The leased infrastructure requires maintenance work, and AWS realized that many of these customers cannot afford specialized database admins, network admins, storage admins, or even server admins. As a result, they created a handful of managed services aiming to cut out admin overhead and let their customer focus on coding. This is how Platform-as-a-service (PaaS) came about.
Let’s take a look at what are exactly operation activities.
Ops activities
IT operation team manages server provisioning, installation of operating system, tuning performance, configuring auto scaling and load balancing, configure networking and storage systems, etc. Networking can be so complex that many infrastructure teams have a dedicated Network Operation Center (NOC), who along with security team, manages key aspects of networking, such as segmentation, router configuration, load balancing, firewall configuration.
For client-server application, the client-side code will make outgoing connections, utilizing the TCP/IP stack on the host through an ephemeral port. The server-side code has to be wrapped as a service. A daemon ensures the process running this service stays up and listens to a TCP port in order to respond to request by invoking the functions. Application team usually assumes these activities.
If database is involved, then the patching, upgrade, replication, data protection are all Ops problems. If storage is involved, then Ops has to manage mass data accumulated over years, the integration between storage and database and applications, performance, replication, etc. Some larger organizations have full-time database administrator and storage administrators.
Then comes container. Containers have their benefits but it increases the operation overhead by an order of magnitude. Running container application at scale warrants its own platform, most likely a Kubernetes platform, to address all of the problems above again at the cluster level. Some organization created platform team to manage container and VM platforms.
It is the Ops, that turns functional code into a running business. It is also the Ops, that becomes a pain point as a startup scales. With IaaS and PaaS models, AWS managed to convince many small businesses to delegate their IT operations to AWS. This is the humble start of cloud computing.
Elastic Beanstalk
At first, I wasn’t too impressed with Elastic Beanstalk, since it abstracts away too many details. However, I later realized that it has been surprisingly popular in the developer community, especially with individual developers and SMBs. It simplifies deployment to the point that their users don’t need to know other AWS services, allowing them to focus on coding application logic.
You configure Applications and Environments (one application may have multiple environments). In the Environment layer, you can specify code platform (e.g. Python 3.8 on 64bit Amazon Linux 2, Java, Go, PHP, Ruby) and even container platform (Docker on EC2 or ECS). Behind the scene, Elastic Beanstalk configures EC2 instances, Elastic Load Balancers, etc on the selected VPC and integrate with logging and monitoring services. In the console, Elastic Beanstalk exposes a list of configurations options (e.g. AMI, instance type). This centralized configuration page is dummied down for those who don’t want to deal with Ops.
The downside of Elastic Beanstalk is it takes away a lot of flexibility. Many developers find Elastic Beanstalk limit their choices of deployment, as their applications scale. Elastic Beanstalk does not suit for applications that demand extensive operation efforts. Its niche market is individual developers and SMB. Few enterprise applications run on Elastic Beanstalk.
Containerization with ECS and EKS
When we containerize an application, we build container images. Then we run these images with container runtimes, is a core feature of container platform. Container platform also provides orchestration engine since we frequently take containers up and down. In addition, container platform provides mechanisms for container networking and storage.
AWS has a couple options for container platform. ECS (Elastic Container Service) came out earlier. It organizes a group of EC2 instances as a cluster. You can manage autoscaling, networking, and persistent storage (EFS, FSx etc) on ECS. EKS (Elastic Kubernetes Service) is the managed Kubernetes service by AWS. Just like AKS, it provides a managed control plane along with computing nodes.
I see ECS as a proprietary and simplified container platform, and Kubernetes as an open-source standard for full-fledged container platform with an entire ecosystem. EKS includes an upstream-certified Kubernetes distribution with a set of tools specific to AWS. Since Kubernetes is the de-facto standard container platform, I prefer EKS by default, unless I can justify the use of ECS. In fact, ECS and Kubernetes have many concepts in common. For example, a “Task” in ECS is equivalent to a Pod in Kubernetes.
Whether it is ECS or EKS, right-sizing the computing node group is always challenging especially when the application traffic load is irregular. AWS Fargate is a technology that provides on-demand, right-sized compute capacities. It works with ECS and EKS. When integrated with EKS, we delegate the node management (e.g. scaling) to Fargate and forget about sizing the node pool.
Using ECS and Fargate involves quite a bit of configurations. To simplify that, we can use App Runner, which builds ECS cluster and uses Fargate to execute the container behind the scenes. App Runner helps client in a way similar to Elastic Beanstalk, but concentrate on Container workload.
Serverless with Lambda and API Gateway
The services above have their limitations when it comes to scaling capability. First, they cannot scale to zero. You still pay for idling resources. Also, it is not easy to find the optimal autoscaling setting. Lambda and API Gateway together solves these challenges. AWS refers to it as serverless, which has since become a buzzword. To understand what it is, let’s examine two concepts:
- Function as a Service: service with the ability to execute code on demand. Users only pay for code execution time and do not care where the underlying runtime is
- Backend as a Service: service with the ability to listen to a port and respond to web request
Lambda itself is a function as a service. Triggered by events, it only incurs a charge when it’s invoked. It does not stay up and listening to a TCP port for incoming web request, as does a backend service. In order to act as a backend, Lambda needs to pair up with API gateway. In this configuration, API gateway listens to a web request, and it fires an event to trigger the execution of Lambda function. Lambda and API gateway together makes a backend as a service. In AWS, the coupling of API gateway and Lambda function ensures an idle service does not incur computing cost.
Since Lambda supports many types of events as trigger, it is also used in event-driven architecture, either standalone or from a VPC. Under the hood, Lambda runs code in a container (with a quick startup time relative to a VM).
Developers can release Lambda code by uploading zip package to S3 bucket, or just packaging code into container image. For deployment, apart from AWS console and CLI, one can leverage CloudFormation, SAM (serverless application model), or CDK.
Lambda vs Fargate
Both Lambda and Fargate are serverless capabilities, at least from a marketing perspective. Both can be used to back web service but there are differences. They provision computing resource at different granularity.
In a web service, the execution duration of a Lambda function is the response duration to an API request, in terms of seconds. While the server is waiting for a request, there is no usage of the computing resource so you’re not paying for waiting for a request. However, this also creates the delay of cold-start, especially when the code size is large. There are several ways to optimize the cold start (e.g. SnapStart for Java), but none of those can completely get rid of the cold-start delay with a once-after-a-while request. A light GET call could take 5 seconds with cold start.
On the Fargate side, the resource provisioning is based on container lifecycle, instead of request lifecycle. As a result, you’re still paying for wait time, and it is not per-request billing. Since the container remains up, your request is not going to experience the cold-start if it’s been idle for a while. Although, Fargate saves you from the effort to right-sizing the computing nodes for container execution, it is not quite the idea of “scale-to-zero when idle” by itself.
Serverless Architecture
In the white paper AWS Serverless Multi-Tier Architectures with Amazon API Gateway and AWS Lambda, AWS advocates the serverless architecture as a modern alternative to the traditional widely adopted three-tier architecture (presentation, logic and data tiers). In the three tier architecture, the scalability of three tier are managed separately. The modern serverless architecture that AWS whitepaper proposes uses API Gateway and Lambda function in place of Load Balancer and EC2 instances (e.g. in an Auto Scaling Group), as illustrated below:
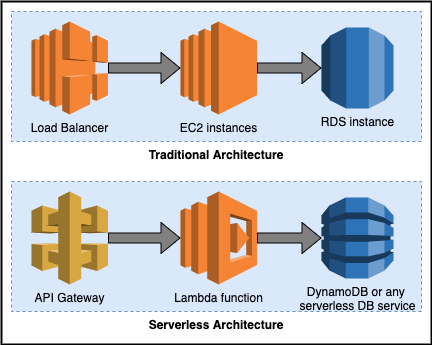
Both API Gateway and Lambda scale automatically to support the need of application workload. It assumes the role of logic tier in three-tier architecture but requires minimal maintenance work. For presentation tier, AWS has serverless alternatives such as CloudFront, S3. For data tier, AWS has serverless alternatives such as Amazon Aurora for relational database and DynamoDB for NoSQL. However, the “no request, no pay” model for Lambda does not apply to the data tier in serverless architecture.
Whilst this paradigm benefits small shop IT who wants to minimize infrastructure cost, it has downsides. There is no ability for infrastructure optimization. Since you do not manage where the code runs, client may have concerns over security (e.g. multi-tenant runtime). As business grows, keep using Lambda can result in technology lock-in. Also, a less used application usually requires warm-up time. A code start (downloading the code and preparing the environment behind the scene) can take 100ms to over a second.
Conclusion
PaaS attempts to help startups simplify the “grunt work” of IT operation. Serverless takes it even further. The semantics of serverless computing is confusing and the Wikipedia page acknowledges it as a misnomer. The nature of serverless model, is the cloud users delegate server capacity management to cloud platforms. The users don’t need to manage servers, VMs, instances, containers, etc on their own. In a previous post, I discussed the ability to scale to zero, which is just one of the many enabling technologies of serverless. Also, “no request, no pay” is neither an inherent nature of serverless model. Serverless service may involve storage (e.g. data service, S3, Aurora serverless) which incurs storage cost. There is a whitepaper on choosing the right AWS service to deploy your website or web application, with a decision tree.
AWS pioneered serverless with Lambda release in 2014 but competitor follows. In the Azure landscape, there is an entire suite of computing services from virtual machine to serverless (also with a decision tree in documentation). Azure’s counterpart for serverless architecture is Azure Function (released in 2016 for GA) with API Management. As for GCP, the serverless suite includes the event-driven Cloud Function (introduced in 2017) and Knative-based FaaS Cloud Run (introduced in 2019).
There are voices in advocacy of standardization of serverless model, and CNCF had since made minuscule efforts such as CloudEvents. The status quo, unfortunately, is anything but standardized.
Lastly, here is a table that summarizes the pros and cons of each computing service model.
| Computing Service Model | Pro | Con |
| EC2 | – Most straightforward and widespread legacy model – Legacy | – Ops tasks can be heavy (e.g. patch and vulnerability management of OS) – Utilization can be low |
| ECS | – Container orchestration is managed – Convenient to scale – Well integrated with other AWS services | – Limited advanced features – Vendor lock-in |
| EKS | – Highly scalable and flexible – Advanced, platform-neutral deployment tools available (e.g. Helm, ArgoCD, etc) – Custom configurations (e.g. operators) | – Significant operation overhead – Steep learning curve (especially for teams) |
| Lambda | – automatically scale – low ops overhead – pay per use | – limited choices of runtime – subject to latency due to cold start; yet warm start incurs cost – not suitable for long running tasks (batch processing jobs etc) |
In summary, the Lambda-based serverless model is good for stateless server-side workload with short response time (<15s), tolerance of cold-start, no need for portability across platforms, and no complex package dependency.