

As a continuation to the last post, we explore the Landing Zone Accelerator on AWS (LZA) as an orchestration tool in this post. LZA borrows a lot from the ASEA, an accelerator project to deploy the security reference architecture (SRA). LZA is a multi-purpose project that consists of both the orchestration engine (the accelerator itself) and a few reference architectures (as configuration files).
Comparison with Control Tower
First, let’s sort out how LZA is related to Control Tower. Control Tower’s main functionalities are available as an AWS service, with some customization capabilities available as a standalone solution on top of the service, as I discussed in the last post. Unlike Control Tower, LZA as a whole is a standalone solution. Luckily, the installation of the solution itself is highly automated.
I see LZA both as an extension of Control Tower, and as a complement to Control Tower. It is an extension of Control Tower because LZA can co-exist with Control Tower. We can configure LZA to enable Control Tower and use its Account Factory to provision new accounts (alternatively but not recommended, we can opt out of Control Tower and manage account creation on our own). I also see LZA as a complement to Control Tower because it comes with full end to end automation scheme for networking infrastructure and most of the services involved. This is missing in Control Tower, which leaves it with users to provision networking infrastructure in the customization.
Thanks to the infrastructure automation capability, even if you do not have a strong regulatory requirement, there are still good reason to go with LZA for its low-code automation capability. Below is a table that summarizes the differences:
| Control Tower | Landing Zone Accelerator |
|---|---|
| – Multi-account management tool – Governance layer – Customization Framework to bring your own infrastructure automation | – can manage Control Tower – low-code automation engine for infrastructure automation and service deployment based on CDK – reference configurations based on common industry profiles and regulatory requirements |
As the name suggests, LZA is an accelerator so there is no expectation of its user knowing how to program infrastructure as code. However, it still expects its users to know YAML very well. Knowing how CloudFormation and CDK works can greatly help the users troubleshoot deployment.
Reference architectures in LZA
The input of LZA is configuration as code in YAML format. The LZA repository comes with a number of sample configurations to implement some industry-based best practices. The reference architectures currently include:
- General best practices reference configuration: for clients other than the categories below;
- Government customers: US Gov Cloud (FedRAMP compliant, on aws-us-gov partition), US State and Local Government, China (on aws-cn partition), Canada Federal (CCCS compliant) TSE-SE (Highly Trusted Secure Enclave Sensitive Edition) on commercial partition for governments, national security, defence, and law enforcement customers reference architecture;
- Election: for election customers including elections agencies, committees and campaigns;
- Healthcare: for healthcare customers. However, the document does not mention HIPAA compliance or anything related to the HIPAA Reference Architecture;
- Finance and Taxation: for tax workload to secure Federal Tax Information (FTI) data;
- Education: for education industry customers.
Many of these reference architecture shares a few common traits in the networking design. Take the CCCS reference as an example, the networking involves the followings:
- Workload VPCs: consisting of a number VPCs for production and test environments;
- Shared services VPC: hosting common services such as pipelines, Active Directories, etc
- Endpoint VPCs: centrally hosting interface endpoints
- Perimeter VPCs: acting as ingress, egress and inspection VPCs.
The Perimeter VPC hosts firewalls (either AWS Network Firewall or NGFW appliances behind Gateway Load Balancers). All the VPCs are centrally managed in an AWS network account, and are shared to other accounts using Resource Access Manager. The reference architecture document keeps the details of this architecture, which was derived from the security reference architecture (SRA).
Special Purpose VPCs
I consider the non-workload VPCs as special purpose VPCs. The shared services VPC is the most straight-forward. The Endpoint VPC is the most standardized. It is used to centrally host VPC interface endpoints for security and cost reasons. Unlike Gateway endpoint which is only available for S3 and DynamoDB, interface endpoint carries a standing charge and therefore should be consolidated. In addition, since interface endpoints are based on interfaces, we can centrally control the security group and interface policy.
To integrate the endpoint VPC, not only do we need to create those interface endpoint. We also need to account for routing (using Transit Gateway route tables) and name resolution. For name resolution, we need to create a Route53 private hosted zone for each DNS name, such as ec2.us-east-1.amazonaws.com and associate them with each workload VPC. Note that the interface endpoints DNS name may not always follow the same format. See the exceptions in my old post. Also note that this would create a lot of associations (between Private Hosted Zone for each Interface endpoint and each workload VPC). For example, 20 workload VPC with 30 private hosted zones will create 600 associations. To overcome this, use Route53 profile (introduced in April 2024).
Another special purpose VPC is the perimeter VPC. This VPC vary greatly between customers because of different requirement and historical preferences. One of the key design areas is the placement of NGFW, which is discussed in this post.
LZA Orchestration Engine
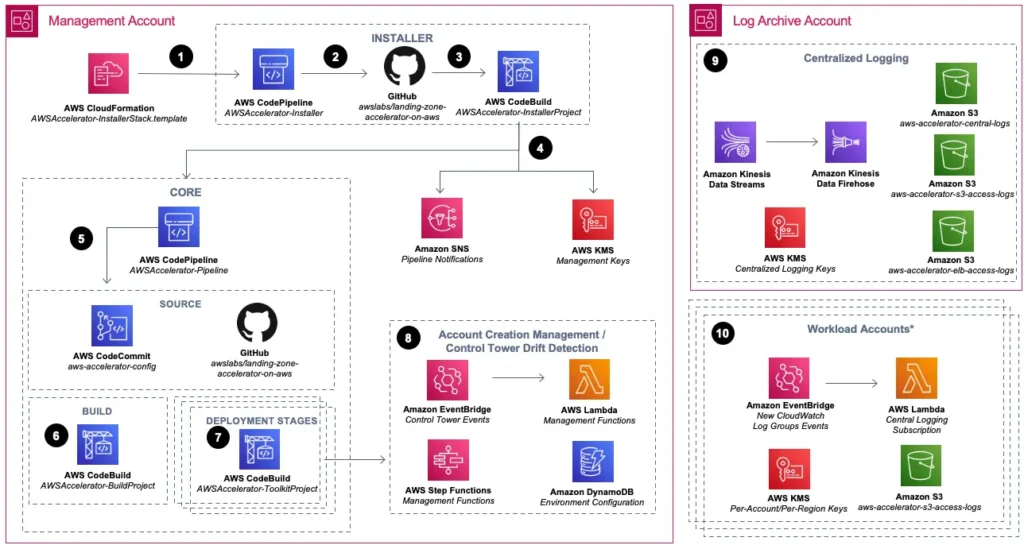
The installation process may feel complex at the beginning because we have to first install the pipeline to that installs the pipeline. The initial setup consists the following steps:
- CloudFormation installs the installer. We start with a CloudFormation template to deploy the LZA installer itself. It deploys resources such as CodePipeline (AWSAccelerator-Installer) and CodeBuild project (AWSAccelerator-InstallerProject). These resources are in the INSTALLER circle in the diagram below;
- The installer installs the accelerator core. In the LZA installer, the CodePipeline (AWSAccelerator-Installer) and CodeBuild project (AWSAccelerator-InstallerProject) drive the installation of the LZA. The input is the official LZA GitHub and we need a GitHub token for this step. The output is the actual LZA orchestration engine, including CodePipeline (AWSAccelerator-Pipeline) and CodeBuild (AWSAccelerator-BuildProject and AWSAccelerator-ToolkitProject). The user may specify their own GitHub repo as the configuration repo. Otherwise, a CodeCommit repo will be created. The LZA resources are shown in the CORE circle in the diagram below;
- The acceleration core configures the landing zone. The LZA orchestration engine deploys actual resources in the landing zone, with the CodeCommit repo (aws-accelerator-config) or the specified GitHub repo as input.
If we enable Control Tower with LZA, we should first log in to management account and configure Landing Zone with Control Tower. we can also create (and register) the required OUs and accounts from Control Tower. Then we can deploy Landing Zone Accelerator with default configuration.
After the initial setup, we will need to iterate over the aws-accelerator-config repo. We implement our landing zone design in YAML configuration following the schema documentation. Changes in the configuration repo will trigger the pipeline (aka LZA’s orchestration engine) to redo step 3, whereas step 1 and step 2 are performed only once. The duration of step 3 is significantly longer than the first two steps.
Pitfalls
If LZA manages Control Tower, it expects existing OUs registered in Control Tower or it will report error. For account, LZA can create accounts listed in the manifest but not yet created. However, with the lengthy account vendor process for multiple account we run the risk of task time out in the pipeline.
During the installation, some account may run into quota limit. For example, the Networking Account usually have more than five VPCs whereas the quota is 5 VPCs per region per account. We need to increase the quota on those accounts.
The full deployment usually creates some SCPs. However, if we ever need to re-deploy a configuration, some steps steps might be blocked by certain SCPs. Attempts to temporarily detach SCPs from OUs, or modify SCPs often get reverted. The cause is an EventBridgeRule in us-east-1 region named RevertScpChangesModifySc. The rule should be disabled temporarily to perform the troubleshooting activity. We can do this with the following steps:
- Disable the EventBridgeRule RevertScpChangesModifySc , which is only present in us-east-1 region;
- Detach SCPs and note down what are detached, one OU at a time;
- Go to the failed CF stack in the region, delete the failed stacks (after turning off termination protection);
- Rerun the pipeline step from where it failed. This time it should go past the failure to the end, if SCP is the cause as per our assumption;
- Re-attach SCPs. Suppose Security and Infrastructure OUs share one group of SCPs, and Dev, Test, and Prod OUs share a different group of SCPs;
- Re-enable the EventBridgeRule;
Even with the EventBridgeRule RevertScpChangesModifySc disabled, when you re-run LZA deployment pipeline, the Accounts step will re-attach the SCPs using the AWSAccelerator-AccountsStack in the management account in us-east-1 region.
Challenges
Powered by CDK, LZA automates the creation of a lot of resources. The configuration files uses the deploymentTargets attribute to allow users to specify to which accounts or OUs the declared resources will be deployed to.
Supporting many resources is a double-edge sword. Because the accelerator needs to go through every aspect of a landing zone, it is very slow to run. The accelerator pipeline may take as long as 40 minutes without any change to the configuration code. This is extremely slow if you just want to make some small changes in the configuration (e.g. update route table, add IAM role).
Even though LZA supports many resources, it’s not flexible with every resource. For example, today we can deploy IAM roles using RoleSet. However, in the trust policy of the IAM role you can only specify a two types of principals under the assumedBy attribute: account and service types. On the other hand a trust policy can support many other types of principals such as another IAM role.

Another important ability that LZA does not support is consistent AZ mapping across accounts. (Correction: this is now supported in LZA v1.5 as of Oct 2023). In some example LZA configurations, we deploy VPCs across multiple accounts using two or three availability zones referenced by their logical ID, such as us-east-1a and us-east-1b. However, AWS maps logical ID to physical ID and the mapping may be different in each AWS account. Using the same logical ID cannot guarantee the physical AZ are the same across account. As of LZA 1.5, the ability to reference physical ID in availabilityZone is supported in LZA configuration file.
Summary
I’ve spent a lot of time on LZA recently. It is extremely powerful. LZA streamlined the landing zone deployment process with configuration as code. It also allows users to customize their landing zone towards their own architectural needs and compliance requirement. For example, you can declare arbitrary SSM parameters in each account.
On the down side, the LZA deployment is time consuming through the pipelines. It tries to automate too many aspects of the infrastructure, which makes itself quite a complex project. Expect lots of changes in each new version.
The idea of being a low-code solution is to make it simple for end users but it often sacrifices flexibility. For example, if you want to create an IAM role in each new account that references the Management account ID, it is not possible until such feature is implemented in the accelerator. When the accelerator pipeline fails, it still requires deep CloudFormation knowledge to troubleshoot.